Generative AI has transformed how we search for information. Put simply, the front door to the internet has changed for the first time in 25 years. But how do chatbots retrieve information, and how reliable are their responses?
Over the past two years, the Research & Development team at Digitalis has analysed over 25,000 sources that sit behind responses generated by ChatGPT, Gemini, and Perplexity. The results challenge some of the prevailing narratives about generative AI.
Read the full report below:
Generative AI has fundamentally altered the way many of us now look up information online. However, for corporate communications and reputation managers, the rules of engagement have not completely changed.
We tend to trust the information generated by AI chatbots, not least because it is presented back to us coherently, succinctly, and confidently.
But how reliable are these new tools? What types of risks do they pose when people use them for research or to follow vital news agendas? How can one exert narrative control within an AI-mediated system?
Chatbots look and feel novel in how they present information to us. But the method by which they retrieve, prioritise, and then serve emergent information back to us remains in large part reliant on traditional online search algorithms.
Prominence in the search index – usually Google and/or Bing (whose index sits behind ChatGPT and Perplexity) – is arguably the single most important factor in determining how the leading chatbots synthesise answers for informational queries.
AI chatbots often simply summarise what search engine ranking systems determine is important.

Over the past two years, we have been analysing over 25,000 sources that inform responses generated by ChatGPT, Gemini, and Perplexity.
The results challenge some of the prevailing narratives about generative AI.
‘Hallucinations’ are a well-documented problem with AI retrieval systems. Unsubstantiated responses are more likely to occur when the user inputs a directional prompt (i.e. seeking specified information about a subject) for which there is a lack of pertinent information within the index. As the model is designed to provide an answer, it can conflate information to create one when there is no good source content.
Declarative and contextual source language helps the retrieval system to match more effectively to user intent.
But there is a much more profound problem when assessing the reliability of chatbots as research tools.
Our analysis shows that, for informational queries relating to people and to entities, approximately two-thirds of the information generated by these models is retrieved from sources that sit across the first pages of the searched indices. Chatbots offer no new powers of discernment that would enable them to generate novel responses. They are merely summarising and reinforcing whatever already ranks prominently in online search, usually for a series of related searches (or ‘query fan-outs’).
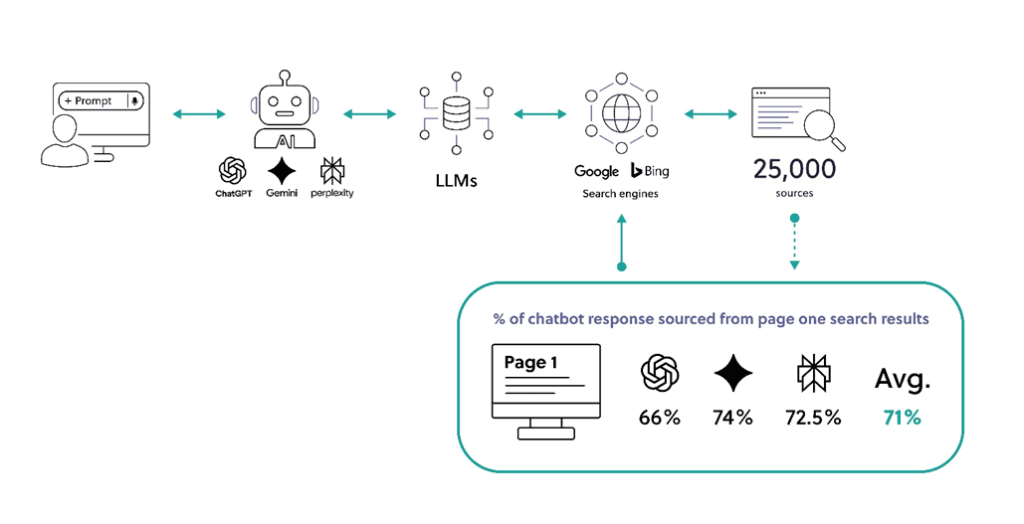
This matters for privacy and reputation management because the leading online search algorithms have been engineered over time to surface information that engages users – measured in clicks, shares, and dwell-time – rather than information that is the most accurate, reliable, or contemporary.
As we are all now too aware, this obsession with showing users ‘engaging’ information is what drives salacious and sensationalist content on the internet and what unfortunately reinforces societal prejudices, polarisation, and diminished trust in our institutions. Content engines know only too well that information triggering negative emotional responses transmits further and faster.
Today this problem is compounded because researchers tend to act upon information leads in chatbot responses more readily than leads generated from traditional search.
For business leaders, investors, and other public-facing economic actors, this built-in negative bias presents vital real-world challenges. If your organisation’s first page of search results is thin on detail, outdated, or otherwise uncontrolled, AI does not – and cannot – correct for that without conflating or hallucinating.
Even when chatbot responses are generated purely from training data rather than live online results (which is rare in the context of prompts pertaining to living people or businesses that are currently in operation), it was the prominence of information within the relevant search indices at the point that data was cached that steers the response. Next time OpenAI, Anthropic, and other AI firms re-train their models (every few months), the prioritisation of information within the index will influence the AI model’s ‘new norms’ following that cache.

First, keep a regular watch on what the popular chatbots are saying about you, your business, or any of its specific interests. If you are not happy with what they are conveying to the outside world, consider taking active measures to better shape their responses.
Second, page-one results matter more than ever because they feed directly into the ostensibly more convincing AI-mediated responses. Regularly check your first-page Google and Bing results and, again, consider taking active measures to improve them.
Third, earned media quality matters more than volume. In our research, a small number of authoritative pieces won out against a large amount of controlled content.
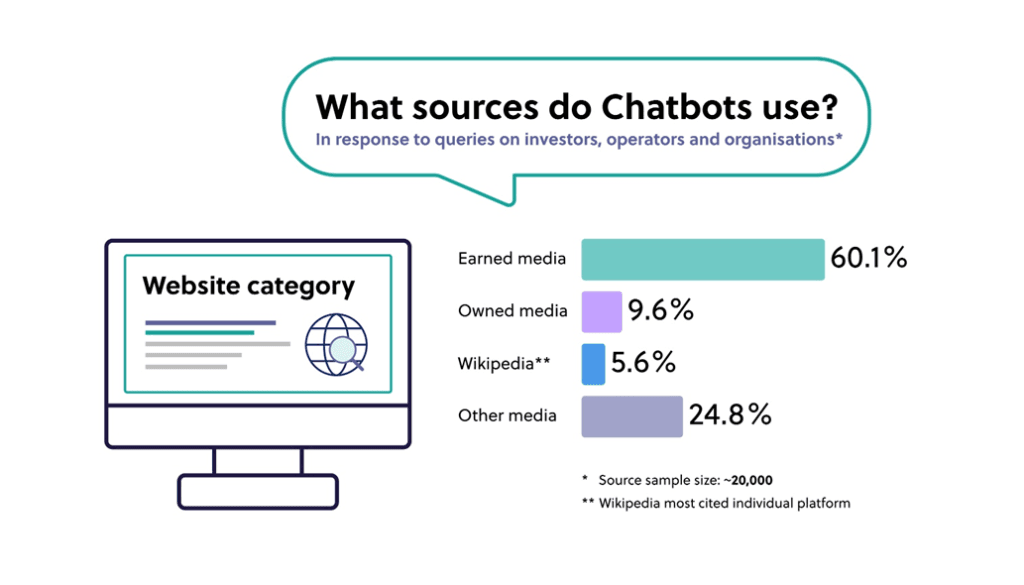
And finally, make sure your owned media assets are factually dense, declarative, and contextualised for the in-bound stakeholder queries you care most about.
The influence of AI-mediated research will continue to increase, particularly as younger cohorts move up through the ranks and new agentic AI workflow systems evolve. This new era of AI-mediated content is no more reliable than traditional online search, and indeed potentially carries new and more acute risks to online reputation, privacy, and security.
Additional reporting by Tom Head.